|
全國兩會正在召開,今年有關“智能化”的提案被多位人大代表提出。“智能+”成為社會關注的重要議題。 語音識別是將語音信息轉變為文字信息的技術。依靠算法和強大的算力,深度學習讓語音交互技術的成果日新月異,應用場景在拓寬的同時也變的越來越復雜,種種因素制約著語音技術的落地效果和速度。 對大眾而言,貼合應用場景的語音交互才具備價值。 “一二陽性是什么意思?” ――“ER陽性是什么意思?” “鄧麗萍 是全國人民代表大會常務委員會委員” ――“鄧力平是全國人民代表大會常務委員會委員” 如上述,專業術語、地名、人名等特殊指代用詞往往影響著對話效果,同樣,環境噪音、方言口音、中英混雜、語速等因素都會對對話效果產生不良影響。通用場景的語音識別性能顯然無法滿足業務的多樣化需求。
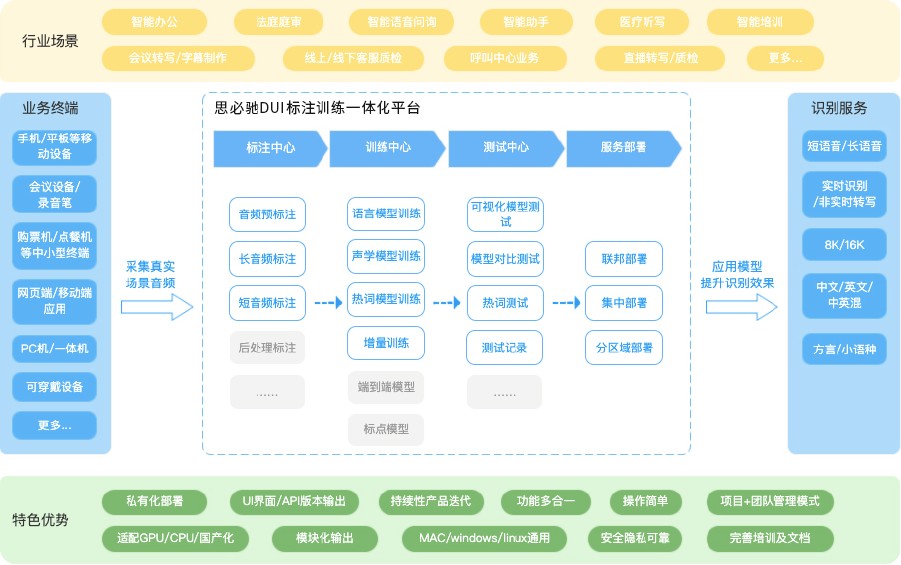
對企業而言,擁有數據標注和模型訓練的能力,掌握自主權,既可實現語音識別的定制化服務,提升識別效果,又可縮短交付鏈路和環節,加速語音技術的落地。此外,對金融、政府、司法、安防等機構而言,掌握數據標注和模型訓練權限,既可以優化語音識別效果,也可以極大的保證數據安全。 思必馳作為專業的對話式人工智能平臺型企業,賦能行業升級,此次重磅出擊,推出思必馳DUI標注訓練一體化平臺。
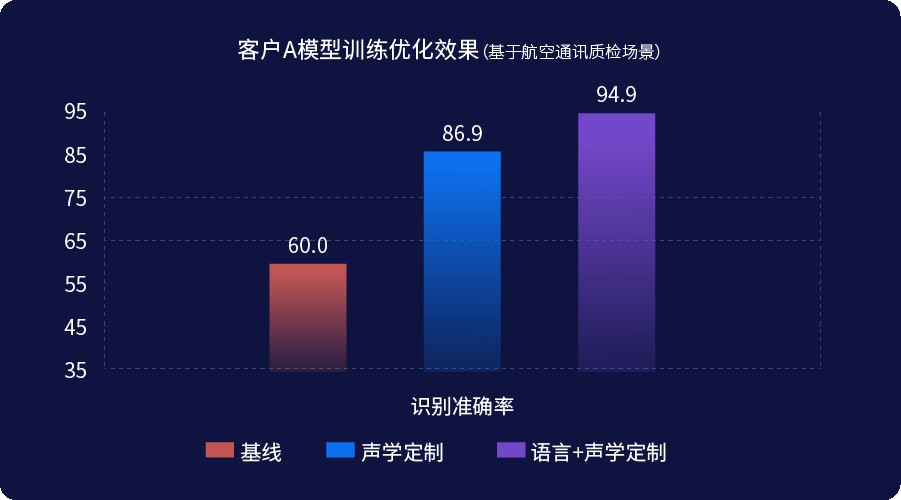
思必馳DUI標注訓練一體化平臺是集成語音標注、模型自訓練、識別測試、服務部署和團隊管理于一體的一站式產品,提供數據標注-模型優化-測試評估-服務部署完整鏈路語音識別自主優化能力,支持私有化部署,協助企業在短期內實現識別效果“不可用-gt;可用”的提升,實現快速更新響應,持續提升場景識別效果,賦能傳統業務AI化轉型升級。 01一低一高,規模化定制 當下,語音交互追求準確性和人性化。 思必馳DUI標注訓練一體化平臺的模型自訓練功能,能大幅度提升識別準確率,尤其是在復雜場景下,可對錯字、漏字、多字、發音不準、方言口音、專業術語等問題進行糾正和引導。據已有項目統計,經過模型自訓練后,應用場景中的語音識別準確率相對提升40。
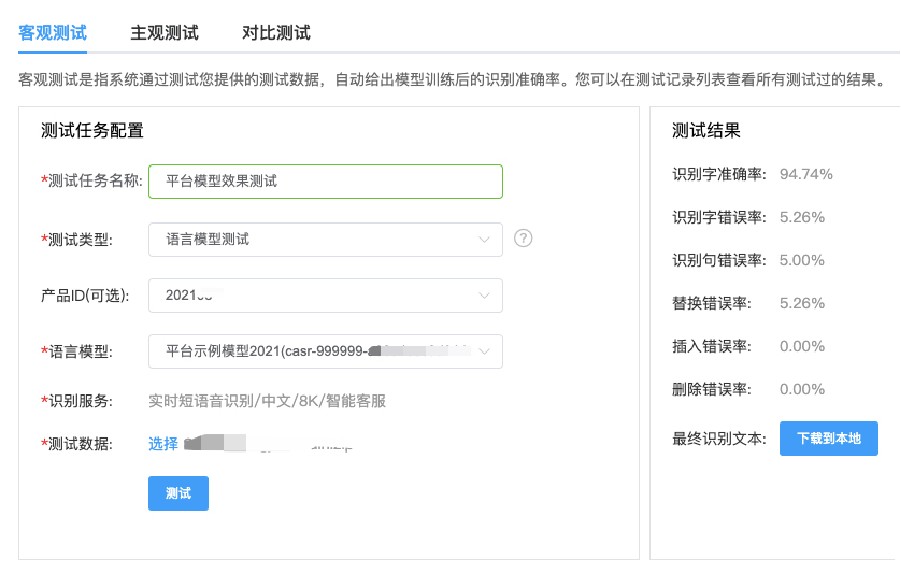
思必馳DUI標注訓練一體化平臺通過“降低 AI 使用門檻”+“高效訓練”+“規模化定制”為用戶降本增效。 降低AI 使用門檻。普通業務人員均可訓練模型,縮短開發周期也減輕企業的人力成本投入。思必馳DUI標注訓練一體化平臺通過融合算法模型、訓練能力、數據、經驗知識,提供一鍵式的模型訓練、發布與部署,含最佳的訓練參數配置,并且,從研究到落地,平臺提供測試工具量化展示模型訓練結果,直觀的進行分析評估讓識別率效果“近在眼前”。
? 訓練模式更高效。基于思必馳的新技術,思必馳DUI標注訓練一體化平臺擁有高效訓練模式,最快可在分鐘級內完成模型訓練,個別詞匯通過熱詞模型訓練方式可秒級熱更新。 平臺的普適性滿足規模化定制的需求。只需簡單的修改配置和收集真實場景的數據,思必馳DUI標注訓練一體化平臺即可應用在政府、金融、醫療、交通、零售、電商等領域,并根據不同行業場景打造垂直領域模型,貼合大規模、可定制的大工業生產階段的需求。 思必馳DUI標注訓練一體化平臺支持Web界面和API兩種接入方式,可配套集成于客戶業務系統,滿足不同類型的客戶需求。“解耦合”的靈活模塊輸出,能夠讓企業級用戶針對特定場景進行高可用和規模化定制,完成自主優化。 02算法是引擎,數據是燃油 大數據積累讓模型更專業 一直以來,思必馳深耕智能終端產品市場及新行業場景,積累了豐富數據資源。使用思必馳DUI標注訓練一體化平臺,用戶可以基于幾萬甚至更多小時數據訓練出的基礎模型,融合真實場景的業務數據,進行更深度的訓練,打造垂直領域的專用模型。同時,思必馳會定期對基礎模型進行更新和優化,使用平臺的用戶,可以按需將模型更新到最新版。 私有化部署讓數據更安全 思必馳DUI標注訓練一體化平臺支持私有化部署和本地化部署,用戶在數據不出庫的情況下進行原始數據標注,完成模型訓練,提升識別準確率。用戶可在自建機房中存儲數據,無需將數據傳輸至外部環境,完美解決敏感數據無法即時可用的問題,確保數據安全。 如今,傳統的通用AI服務已經很難滿足業務場景需求,AI正在向賦能用戶擁有自主學習能力轉變。基于思必馳在語音交互領域數十年的積累和經驗,思必馳DUI標注訓練一體化平臺,通過平臺化的方式開放智能語音算法能力,將優質的語音技術、海量數據資源和開發自主權交給企業,讓產品的智能化升級如虎添翼。 |
- 關注天氣: