|
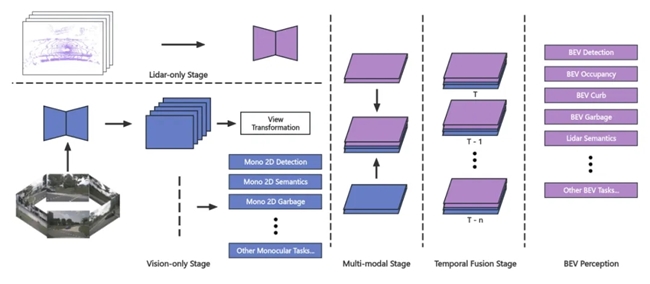
當前,中國自動駕駛滲透率和商業化步伐正在加速,感知系統作為實現高階自動駕駛關鍵技術之一,吸引行業廣泛關注,成為衡量自動駕駛企業技術競爭力的核心戰場。 作為無人駕駛商業化領先企業,仙途智能深耕自動駕駛領域,憑借其全棧自研的無人駕駛技術棧和在乘用車、商用車以及垂直場景的深厚積累與場景拓展,在感知方面形成了完整、成熟的技術體系,自主研發了業內領先的兼具多任務、多模態、跨時序等特點的BEV多任務感知模塊以及支撐BEV快速迭代的數據閉環系統。 垂直場景下仙途智能BEV感知技術突破 在傳統的無人感知技術棧中,2D圖像輸入到感知模塊以生成 2D感知結果,然后利用傳感器融合技術對來自多個相機的2D結果、激光雷達的結果進行推理后傳給下游。在這個過程中需要大量手工制定的規則,同時面臨著遮擋、觀測不全、信息損失等問題。為了克服以上問題,BEV技術將多傳感器特征統一在同一個3D空間內,減少信息損失,以一種更簡潔高效的、端到端的方式直接在3D空間內進行感知。基于BEV技術,仙途智能構建了一個面向環衛場景特色和作業需求的BEV多任務感知系統,具有以下特點:
圖1:BEV多任務處理 多任務處理,應對復雜場景下感知挑戰:為滿足復雜多變的環衛作業需求,仙途感知模塊不僅支持傳統交通場景中的常見檢測任務如車輛、行人、交通標志等,還針對環衛場景新增低矮障礙物檢測、路沿檢測、垃圾檢測、揚塵水霧識別過濾、可碰撞檢測等任務。同時,相比于每個任務單獨1個小模型的方案,BEV多任務感知模塊使用共享骨干網絡的網絡結構,計算負擔降低30以上,確保了自動駕駛車輛的實時環境感知能力。 多模態融合,提供精準、實時的感知支持:BEV感知推理以環視圖像、多激光雷達點云作為輸入,具備跨多模態、跨多傳感器的信息聚合能力,能夠補齊單模態感知的短板。仙途智能BEV感知精度相較于純視覺算法提升32.6以上,單激光點云感知算法提升18.9以上。同時具備可拓展性,能進一步接入更多傳感器數據。 跨時序感知,實現精準目標速度預測:BEV感知具備多幀點云輸入和多幀特征聚合的跨時序感知能力,能夠在長時間范圍內補全當前幀中的信息缺失,提升感知精度,并具備更精確的目標運動速度預測能力。 可以通過以下場景實例,深入了解仙途智能的BEV多任務感知技術是如何高效解決復雜交通場景中的挑戰以及處理長尾問題。 場景實例:BEV多任務感知模塊在復雜場景下的應用實踐 場景1:提升低矮障礙物檢測精度,確保自動駕駛車輛高效作業 低矮障礙物是無人環衛極具挑戰的場景之一:1.相比常見的車輛、行人等交通參與者,低矮障礙物呈現出種類繁多、數量稀少的長尾分布特點,如水管、石塊、倒地的鐵鏟、坑洞、保溫杯等;2.由于部分低矮障礙物形狀大小各異,激光雷達往往無法穩定掃描到;3.對于無人駕駛車輛而言,必須精準判斷哪些障礙物需要繞行以避免碰撞,哪些又可以安全地進行清掃作業;4.即便是相同類型的障礙物,其大小、狀態及內容物的不同也會顯著影響決策結果,例如,細小的枝條可以直接清掃而不必繞行;然而,粗壯的大枝條則可能因堵塞清掃設備的吸口而需要車輛采取繞行策略。 針對上述挑戰,仙途智能設計了一套以視覺為主、激光為輔的、結合2D+3D的多傳感器檢測方案,同時通過引入對障礙物的屬性預測+occupancy預測,并結合垃圾檢測技術,能夠準確預估障礙物的尺寸、高度等關鍵參數,從而有效輔助決策系統判斷是否需要繞行或進行清潔作業。
圖2:玫紅色色塊為低矮障礙物識別結果:黑色細水管
圖3:玫紅色色塊為低矮障礙物識別結果:黑色垃圾袋
圖4:玫紅色色塊為低矮障礙物識別結果: 黑色垃圾堆與展開的塑料布袋
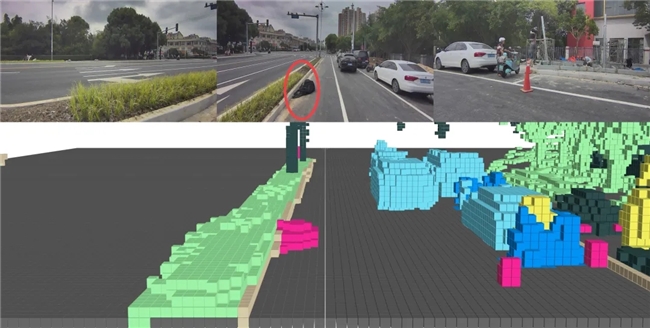
圖5:玫紅色色塊為低矮障礙物識別結果: 不可以清掃的白色垃圾堆 上述4張圖片分別顯示了自動駕駛車輛在遇到低矮障礙物的情形,從圖2到圖5,其作業場景地面上分別有黑色細水管、黑色袋子、黑色垃圾堆與展開的塑料布、不可清掃的白色垃圾堆。 可以看到,當自動駕駛車輛行駛在上述四個場景中,仙途智能BEV感知模塊輸出的occ占據柵格有不同的顏色色塊,低矮障礙物識別的位置精度和朝向都非常準確,為自動駕駛車輛在復雜的路面環境下安全作業、順暢地行駛提供了強有力的保障。 場景2:復雜路況的3D目標檢測,提供更全面的環境感知 在復雜道路狀況下,感知系統面臨挑戰諸多:交通擁堵中人車混行,目標密集與遮擋、不規則路面的感知與適應、動態變化的環境與突發情況等。
圖6:仙途智能BEV感知在繁忙路口的3D檢測綜合能力對狹窄道路上眾多擦肩而過的交通參與者穩定檢出及動態預測 如圖6,在繁忙的交通路口中,車輛來自各個方向,包括同向行駛的車輛、反向行駛的車輛、準備轉彎的車輛,以及大量占用車道或人行橫道的行人、自行車等,仙途智能BEV感知系統在這樣環境下檢測出車輛周圍的障礙物、行人、自行車的位置、速度、方向和尺寸等信息,為自動駕駛車輛在行駛作業中提供了周圍環境全方位、360度精準感知。 場景3:BEV路沿檢測,位置與形狀的高精度識別與追蹤 在環衛作業場景中,無人駕駛車輛需要實現貼邊清掃,這就要求車輛能夠準確識別并追蹤路沿的精確位置和形狀,以確保清掃作業的準確性和安全性。但現實道路環境復雜多變,路沿的不同形態直線、曲線、折線,以及路沿上覆蓋的不同物體植被、低矮,都對路沿識別的準確度和魯棒性形成了挑戰。 為此,仙途智能在BEV網絡中引入BEV路沿檢測任務,將路沿劃分成不同網格,利用深度學習網絡提取圖像與激光雷達對應的特征,擬合出各個網絡內部的路沿,再結合幾何特征與地圖先驗進行拼接,以實現對不同形狀路沿準確識別;同時,路沿檢測任務引入時序信息,結合多幀結果進行濾波,進一步提升了結果的穩定性。
圖7:BEV路沿檢測,精確檢測路沿彎度與位置紅色曲線為路沿檢測結果 如圖7顯示,仙途智能BEV感知系統精確顯示了彎道中路沿的彎曲程度,使車輛根據路沿信息選擇合適的速度,確保高貼邊率。 場景4:3D語義分割,有效識別環境中的水霧、灰塵 由于環衛場景的特性,無人駕駛車在灑水作業或行駛時揚起的水霧和灰塵,經激光雷達檢測容易形成障礙物,影響正常通行。為此,仙途智能BEV感知系統通過結合圖像、激光雷達預測每個激光點的語義信息,實現對自車揚塵、水霧和他車濺水的識別和過濾。
圖8:水霧處理前
圖9:水霧處理后 如圖8無人駕駛車輛灑水作業場景中,車輛周圍被密集的水霧所籠罩,單從點云模態來看會誤檢成障礙物。BEV感知系統通過多模態的點云語義分割技術,精確識別并剔除這些由水霧產生的噪點有效降低了惡劣天氣和灑水作業對自動駕駛車輛感知精度的影響圖9。 仙途智能構建高效數據閉環,加速研發迭代,實現降本增效
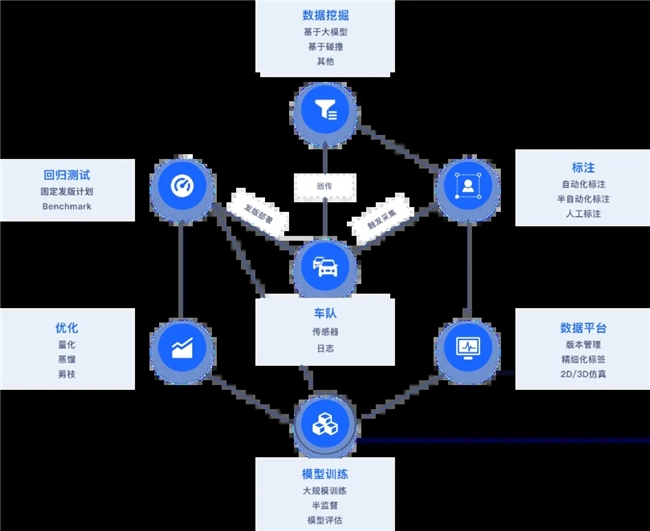
圖10:數據閉環方案 數據閉環已經成為自動駕駛解決長尾問題的核心策略與關鍵路徑,如何對數據進行大規模高效處理并快速優化算法模型,成為自動駕駛技術迭代的關鍵。仙途智能的無人駕駛車輛已在全球累計行駛超過1300萬公里,基于這些海量數據,通過構建高效的數據挖掘-標注-仿真-模型迭代的數據閉環圖10,實現自動駕駛技術的快速迭代和降本增效。 數據挖掘,豐富長尾數據庫
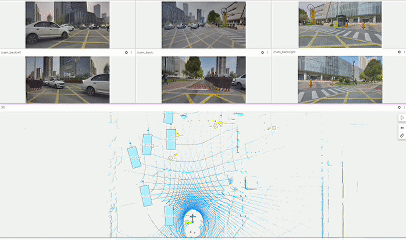
圖11:特定場景數據挖掘 如圖11展示了仙途智能通過大模型進行長尾場景數據挖掘的示例。仙途智能構建了基于文字到圖像的多模態模型,當需要獲取特定類型的場景數據,只需通過自然語言文字描述,比如“非站立行人”,即可從海量歷史數據中自動挖掘符合條件的場景數據,提高了挖掘長尾場景的效率,基于挖掘出的場景數據則會進入自動/半自動標注處理,用于模型訓練。 數據自動標注,實現成本節約與效率提升
圖12:3DBox自動標注:藍色黃色box為自自動標注的車、人,其中箭頭標注了其朝向 針對海量未標注的數據,仙途智能一方面通過半監督、數據增強等方式提高未標注數據的利用率相關工作發表于CVPR2022、ECCV2022和ICRA2024;另一方面研發基于BEV多模態的自動標注系統,成倍提升了標注效率,大大縮短了模型迭代周期,顯著降低標注成本。 2D數據仿真+3D數據仿真,提升BEV感知模型泛化能力 在數據仿真層面,仙途智能通過2D和3D數據仿真相結合,模擬出高保真的長尾場景,豐富了自動駕駛算法的訓練數據,為自動駕駛感知算法模型提供更全面的訓練和測試環境。
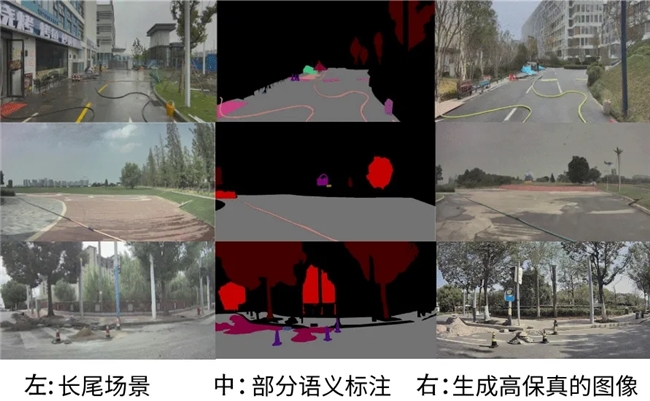
圖13:2D數據仿真實例 如圖13展示了2D數據仿真的實例。針對在實際運營中遇到的長尾場景如圖13左,仙途智能通過大模型或者人工對該類場景進行部分語義標注如圖13中,再由Diffusion Model生成高保真的圖像,其中水管、桶、交通錐等經過標注的障礙物與原圖具有較高的語義一致性,背景等未經過標注的障礙物也接近真實場景如圖13右。通過這種多場景的生成與訓練,仙途智能的自動駕駛車輛能夠更好地適應各種復雜和不可預測的道路環境,從而提高整體的安全性和可靠性。 在3D數據仿真技術的應用實踐中,仙途智能通過3D Gaussian Splatting技術對長尾場景進行重建,從而生成Corner Case高保真的新視角視圖,顯著豐富了長尾場景庫,更好支持感知模型的訓練和新場景測試。
圖14:車輛正常經過的場景
圖15:場景建模后,生成的新視角數據 如圖14呈現了車輛在正常行駛途中記錄的場景,圖中左側懸空的細長警戒線屬于駕駛過程中較為罕見的元素,對自動駕駛感知系統構成了極大挑戰。仙途智能采用3D仿真技術生成了包含警戒線等這些障礙物在內的高保真的全新視角視圖見圖15,尤其是懸空警戒線出現在前進道路這一關鍵視角,從而支持了“前進道路上出現懸空警戒線”這一新場景的測試,有效提升自動駕駛系統面對復雜環境時的泛化能力與魯棒性。 以上,系統展示了仙途智能在自動感知系統領域所取得的技術革新與應用實例。未來,仙途智能將繼續堅持“軟硬結合”的技術路徑,積極探索感知技術應用場景,分享最新研究成果,聚焦自動駕駛商業化落地,推動自動駕駛技術革新。 |
- 關注天氣: