|
TensorFlow 的「物體檢測 API」有了一個新功能,它能根據(jù)目標(biāo)對象的像素位置來確定該對象的像素。換句話來說,TensorFlow 的物體檢測從原來的圖像級別成功上升到了像素級別。 使用 TensorFlow 的「物體檢測 API」圖片中的物體進(jìn)行識別,最后的結(jié)果是圖片中一個個將不同物體框起來的方框。最近,這個「物體檢測 API」有了一個新功能,它能根據(jù)目標(biāo)對象的像素位置確定該對象的像素,實現(xiàn)物體的像素分類。
實例分割「實例分割」是物體檢測的延伸,它能讓我們在普通的物體檢測的基礎(chǔ)上獲取關(guān)于該對象更加精確、全面的信息。 在什么情況下我們才需要這樣精確的信息呢?
「實例分割」的方法有很多,TensorFlow 進(jìn)行「實例分割」使用的是 Mask RCNN 算法。 Mask R-CNN 算法概述
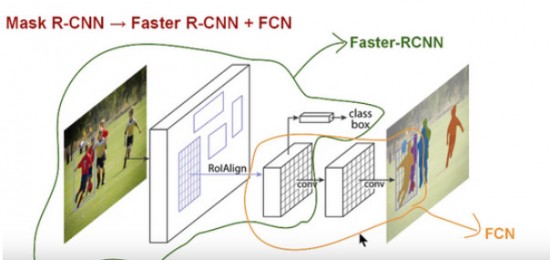
Mask RCNN 算法架構(gòu) 在介紹 Mask RCNN 之前,我們先來認(rèn)識一下 Faster R-CNN。 Faster-RCNN 是一個用于物體檢測的算法,它被分為兩個階段:第一階段被稱為「候選區(qū)域生成網(wǎng)絡(luò)」(RPN),即生成候選物體的邊框;第二階段本質(zhì)上是 Fast R-CNN 算法,即利用 RolPool 從每個候選邊框獲取對象特征,并執(zhí)行分類和邊框回歸。這兩個階段所使用的特征可以共享,以更快地獲得圖像推算結(jié)果。 Faster R-CNN 對每個候選對象都有兩個輸出,一個是分類標(biāo)簽,另一個是對象邊框。而 Mask-RCNN 就是在 Faster R-CNN 的兩個輸出的基礎(chǔ)上,添加一個掩碼的輸出,該掩碼是一個表示對象在邊框中像素的二元掩碼。但是這個新添加的掩碼輸出與原來的分類和邊框輸出不同,它需要物體更加精細(xì)的空間布局和位置信息。因此,Mask R-CNN 需要使用「全卷積神經(jīng)網(wǎng)絡(luò)」(FCN)。 「全卷積神經(jīng)網(wǎng)絡(luò)」是「語義分割」中十分常見的算法,它利用了不同區(qū)塊的卷積和池化層,首先將一張圖片解壓至它原本大小的三十二分之一,然后在這種粒度水平下進(jìn)行預(yù)測分類,最后使用向上采樣和反卷積層將圖片還原到原來的尺寸。 因此,Mask RCNN 可以說是將?Faster RCNN 和「全卷積神經(jīng)網(wǎng)絡(luò)」這兩個網(wǎng)絡(luò)合并起來,形成的一個龐大的網(wǎng)絡(luò)架構(gòu)。 實操 Mask-RCNN
你可以利用 TensorFlow 網(wǎng)站上的共享代碼來對 Mask RCNN 進(jìn)行圖片測試。以下是測試結(jié)果:
最有意思的是用 YouTube 視頻來測試這個模型。從 YouTube 上下載幾條視頻,開始了視頻測試。 視頻測試的主要步驟:
Mask RCNN 的深入研究下一步的探索包括:
|
- 關(guān)注天氣: